

Quick Summary: The present-day infrastructure flourishes in distributed environments. This is where Observability comes in. Observability refers to the measurement of the internal state of the system by examining the outputs. This blog covers an inclusive view of Observability, including its Objectives, Working processes, Tools, Best practices, Advantages and Disadvantages.
Over the past 20 years, IT teams have greatly relied on Application Performance Monitoring (APM) to track applications as it regularly samples the system data, which is generally known as telemetry. This APM is beneficial for inspecting and troubleshooting applications.
But as developments took place, organizations started choosing modern development practices – DevOps, agile development, continuous deployment, and microservices. As organizations increasingly endorse intricate, multi-layered, cloud-based infrastructure utilizing microservices, observability has become an important cornerstone. Achieving observability requires a significant boost in the volume and quality of the telemetry data, enabling the detailed records of every application user interface.
Observability vs Monitoring
Observability and monitoring are two key concepts used in DevOps, software engineering and system administration. Though they are related to each other, they are two different terms. To have a better understanding let’s take a look at their key differences.
Observability
Observability is the capacity to learn a system’s internal state by evaluating the data such as metrics, logs and traces. This is considered important because it provides greater control over complex systems.
Monitoring
Monitoring is a process used to collect, examine, and interpret data to detect performance, decrease the negative effects of a process or system, and enhance beneficial effects. It allows us to watch specific metrics. Generally, monitoring is essential for examining long-term trends, alerting and building dashboards.
Let us now trace the difference between Observability and Monitoring.

How can Observability be Achieved?
Observability can be attained through a blend of observability tools and platforms, enablingthe development team to identify the system issues and achieve the business goals. By inspecting all the inputs, observability provides a better understanding of the distributed system.
Moreover, the goal of observability are as follows
-
Identify and link effects in a complex chain
-
Effectively monitor modern IT systems
-
Attain visibility through system administrators and IT operation analysts
-
Experiment and implement the optimizations safely
-
Effectively manage business risks and handle issues before they affect customers
-
Upgrade knowledge transfer across team boundaries
Objectives of Observability
Having understood the details of observability and its goal, let’s now take a glimpse at its objectives.
-
Business Success
Performance and system availability are crucial for business success, as non-availability and underperformance negatively impact customers, affecting user satisfaction and customer experience. In some cases, it can also lead to revenue loss, business failure, or even reputational damage.According to the survey conducted by Cloud Native Observability Report 2023

In a complex environment, it is impossible to keep track of observations. Thus, identifying and correcting the system issues before they have a greater impact can help resolve performance issues. -
Security and Compliance
Observability also plays an important role in ensuring businesses abide by their legal obligations to safeguard sensitive data against unauthorized access. To prevent data breaches, observability tools can be used from a security perspective.
-
Marketing
The observability practices can lead to a profitable and revenue-growing business, thereby boosting user experience. There are various ways in which growth can be measured. For example – analytical data about customer behaviour can help us make strategic decisions.
How does Observability work?
Observability works on three primary sources of data, also called the three pillars of observability – logs, metrics and traces. By constantly gathering these types of data, the observability platforms can provide contextual information.
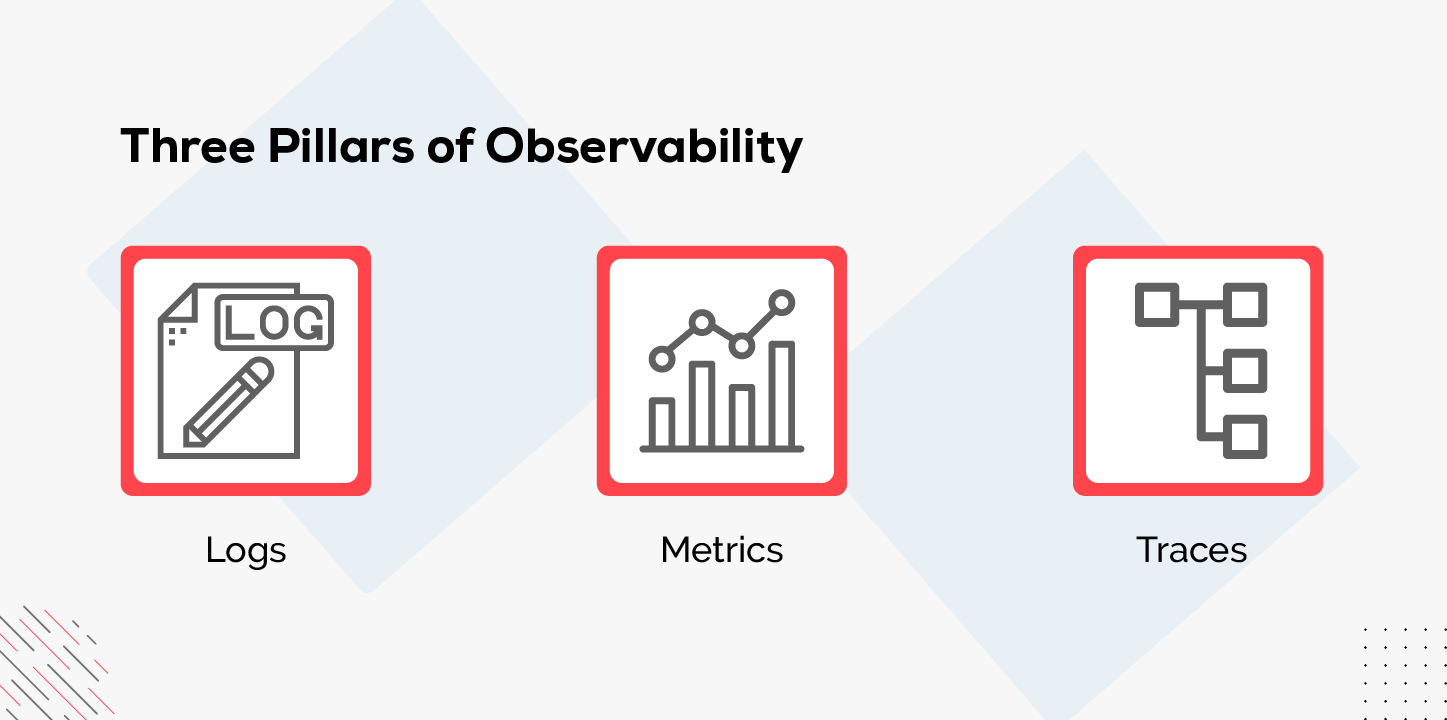
In brief, by working with the pillars of observability, the teams can easily identify and solve problems in real time.
Let us explore more about the three pillars of observability.
Logs
Logs are records of events that occur over time, containing detailed information. Generally, logs are easy to execute as software libraries and languages often have built-in functionalities. Mainly, developers are accountable for logging in code. In some cases, logs can be analytical or historical, providing context in operations management.
Metrics
Constantly, the data is measured through numerical value and recounts the overall behaviour of a service. Observability metrics measure response time, CPU Capacity, error rates, peak load and latency. These key performance indicators
-
Detects events for unique activities
-
Assess performance
-
Generates alerts when necessary
Traces
Traces are considered information pathways that follow a unit of work. The source of an alert can be identified through traces, accurately showing where tracking system dependencies are occurring.
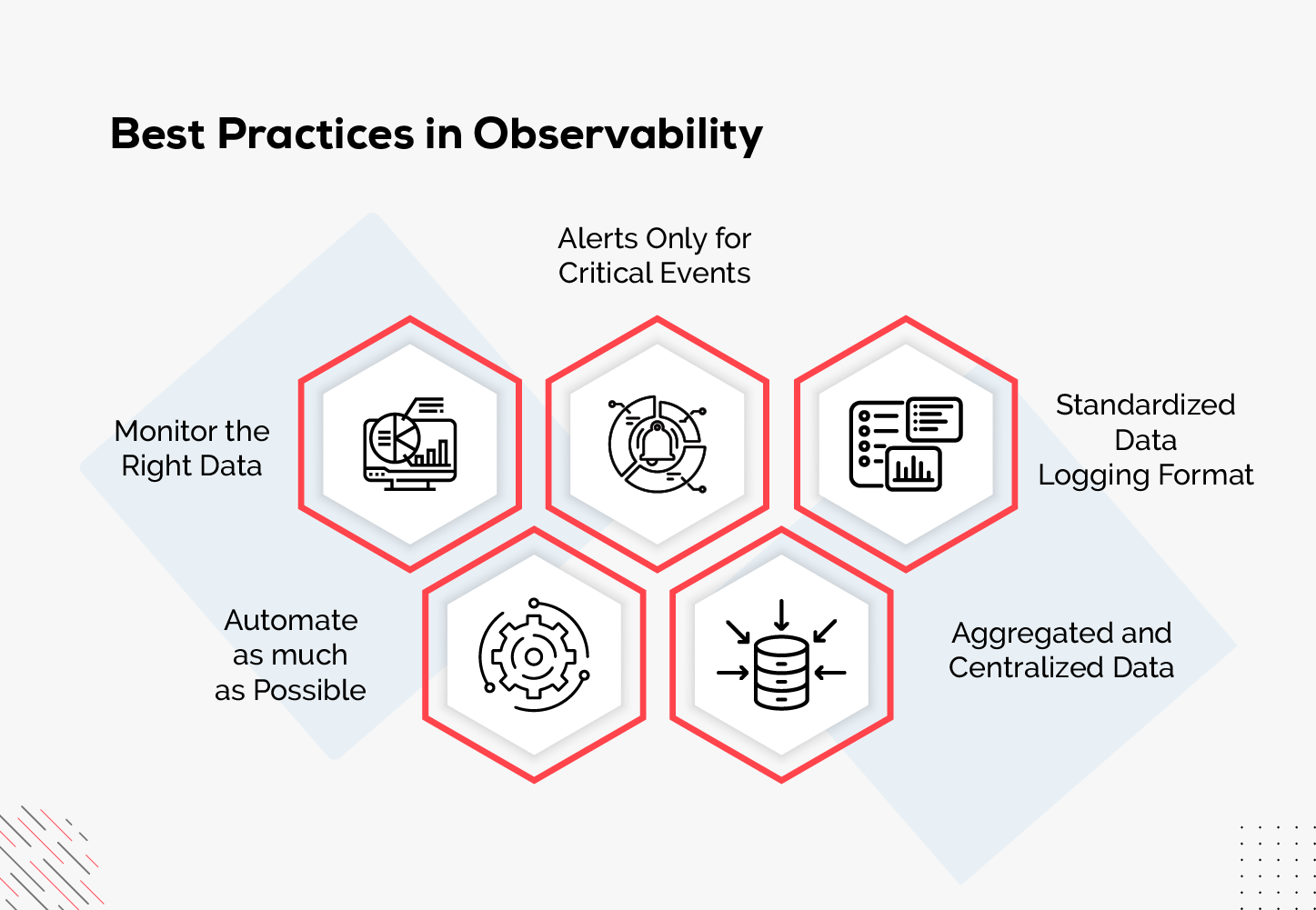
Best Practices in Observability
Organizations can achieve a high degree of observability if the best practices are followed. Delve deeper to learn more about the best practices in Observability.
-
Monitor the Right Data
Monitoring the data is more important than collecting it, as it helps in achieving the business objectives effectively. The observability platform should be planned to filter data close to the source. -
Alerts Only for Critical Events
Notifications can be created and configured to detect important events in the system. Developers can detect problems and fix them when something goes wrong. An observability tool like Middleware works effectively on critical early-stage problems. -
Standardized Data Logging Format
DevOps teams can identify issues from the data produced by logging, and the root cause of the issue can also be detected. Therefore, by structuring logs, the data should be formatted to maximize its usage. -
Automate as much as Possible
Manual monitoring takes time and can sometimes be error-prone. To achieve observability, automation is the key and choosing automation to collect data, initiate remediation actions and detect anomalies would be the perfect choice. -
Aggregated and Centralized Data
To attain observability, data must be gathered, stored and examined. A more comprehensive view can be achieved by aggregating data from various sources.
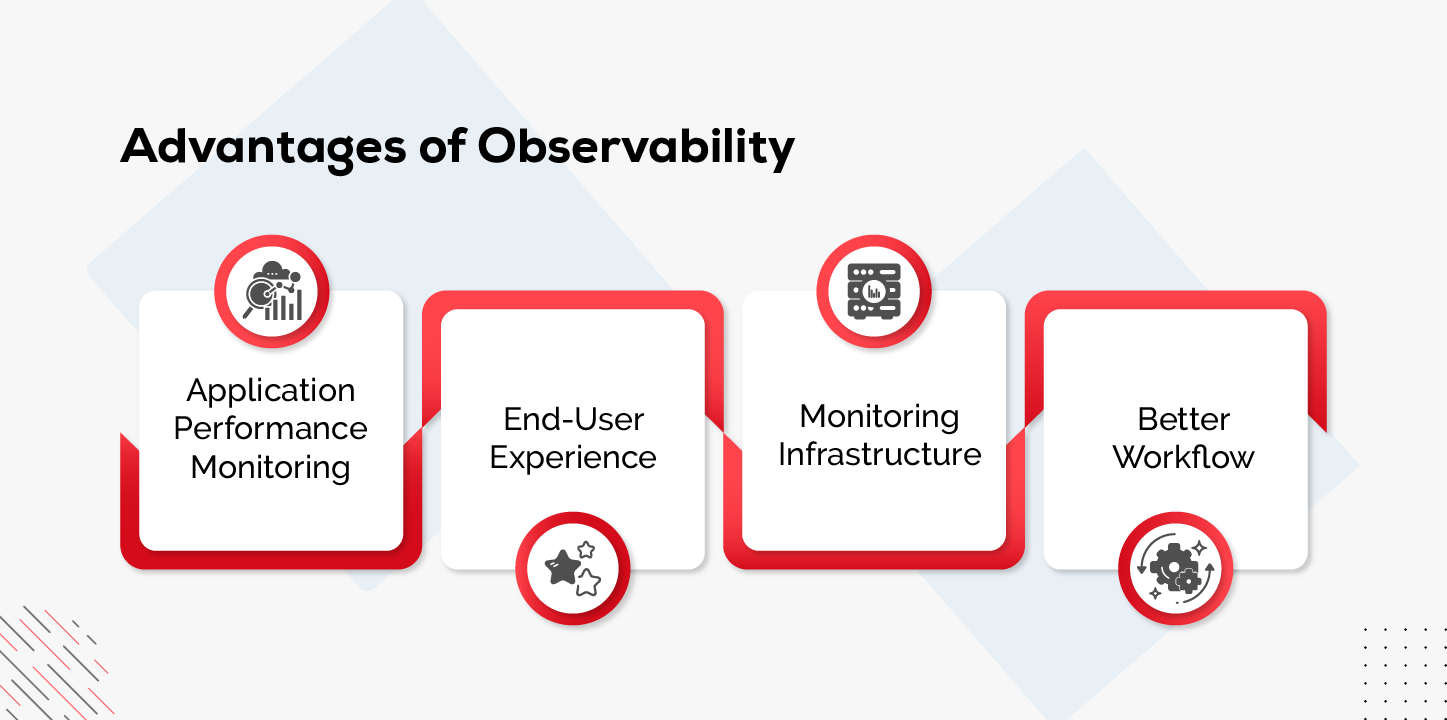
Advantages of Observability
Observability brings benefit to enterprise, IT teams, and end users. Below are the advantages of observability. Take a close look at each of these benefits.
-
Application Performance Monitoring
The end-to-end observability allows businesses to identify errors more quickly. With an advanced observability solution, large tasks can be automated, thereby increasing productivity. -
End-user Experience
Generally, business reputation and income can be increased by a positive user experience. By fixing problems and implementing improvements, you can help to gain customer satisfaction. -
Monitoring for Infrastructure
One of the significant advantages of observability is that it helps to enhance Infrastructure Monitoring. Additionally, the observability solution offers increased performance and reduces the time required for fixing problems. -
Better Workflow
Observability allows developers to view the end-to-end journey as well as data relevant to specific issues and optimize its performance.
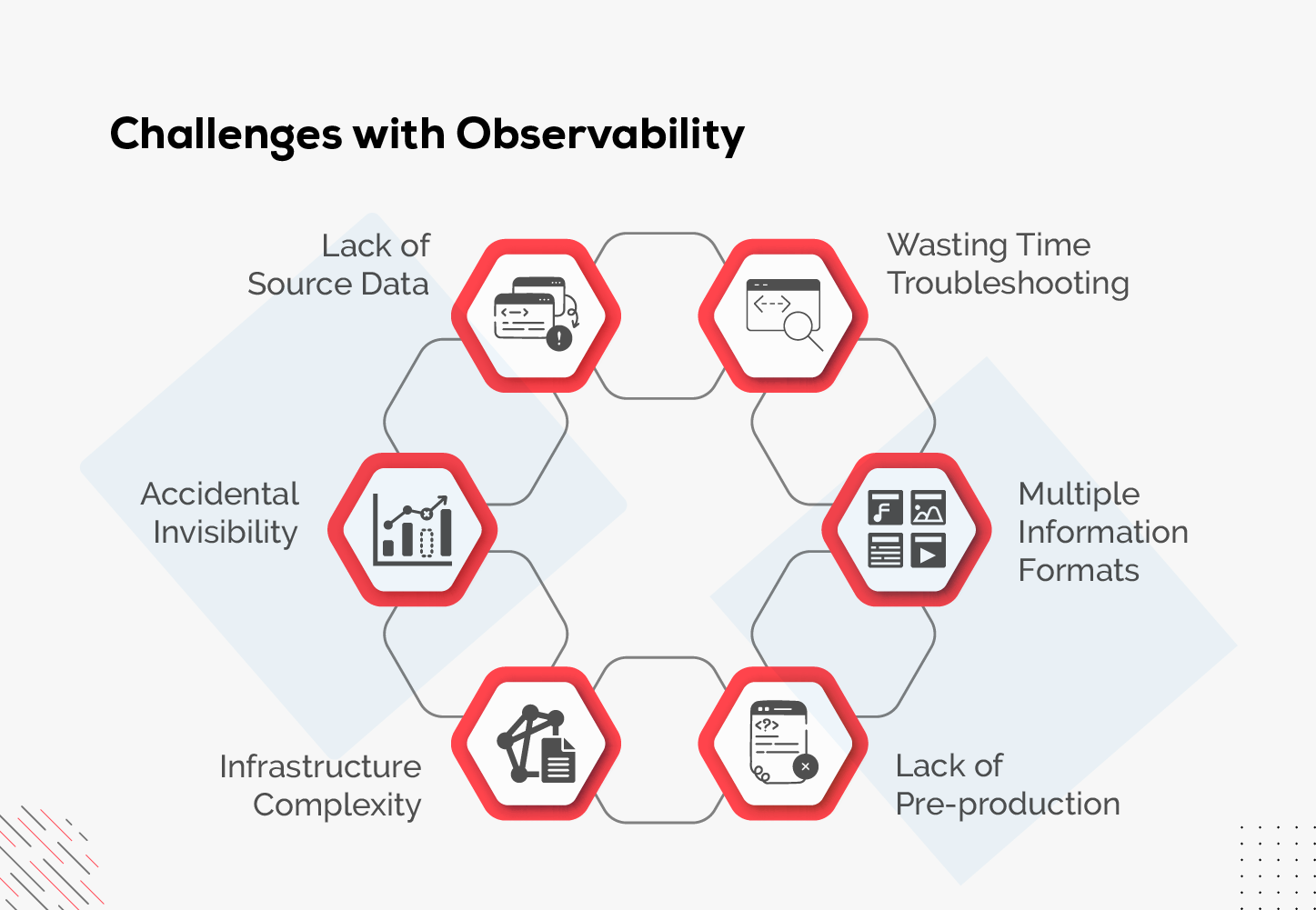
Challenges with Observability
Let us discover the challenges with observability that you must overcome.
-
Lack of Source Data
At the application level, not all information is collected, especially when it comes to tracking workflows, making it challenging to collect source data. Typically, tracking workflows requires special software modifications. -
Accidental Invisibility
Accidental invisibility occurs when structured data or filtering is not done properly. This leads to missing data as it gets hidden from view. -
Infrastructure Complexity
Implementing observability systems is challenging due to dynamic multi-cloud environments, requiring significant changes to existing systems. Additionally, monitoring microservices and containers poses its own set of challenges. -
Wasting Time Troubleshooting
The teams for application, operation, and development are called in to discover the root cause. This leads to wasting time on troubleshooting. -
Multiple Information Formats
Telemetry data from various sources should be implemented to gain multiple information. However, it can be a bit challenging to trace out the correct information as the same data enters from various sources in multiple formats. -
Lack of Pre-production
The data collected in pre-production environments leads to inaccurate or incomplete information, as it may not accurately display a real-world production environment.
Effective Observability Tools
Attaining observability is a bit challenging in today’s evolving technological world. A wide range of observability tools is available, each with its own importance. Further, these tools help us detect the state of the system, identify issues and measure component performance.
The observability platform helps us quickly solve the issue by combining the logs, metrics and traces. In addition, these effective observability tools offer a variety of advanced visualizations and alerting systems. Here is a list of the top observability tools.
Application Performance Management Tools
Netreo
Netreo is a monitoring tool that helps with IT infrastructure monitoring, code profiling capabilities, and application performance monitoring. It provides visibility into IT infrastructure, including applications in the cloud, network devices, hybrid environments and on-premises.
Splunk
This unified security tool offers real-time insights. Splunk covers synthetic monitoring, log management, and infrastructure management. Moreover, this tool is known for its flexibility. Additionally, it collects data from various sources and provides a single dashboard view. Organizations looking for greater visibility into IT environments across multiple services opt for the Splunk tool.
UptimeRobot
UptimeRobot is a monitoring tool that delivers monitoring services to all sizes of organizations. Some of its key aspects include:
-
Sends alerts through mail, push notifications and SMS.
-
Provides server monitoring and website services.
-
Offers email reports and logs for examining response time.
Open-Source Tools
Prometheus
This open-source tool is specifically used for real-time monitoring and alerting of applications. Prometheus enables the gathering of metrics and generation of basic alerts in Kubernetes. Due to its flexibility, it is widely used by DevOps teams.
Grafana
Grafana is considered the greatest tool as it is easy to understand and is specifically made for metrics visualizations. Furthermore, it is commonly used with database sources like Graphite.
Log Management Tool
Dynatrace
Dynatrace is an observability tool that offers infrastructure monitoring, and log management. In addition, this tool allows you to monitor the security and performance of cloud applications.
Apart from these tools, numerous effective observability tools help you to check observability. Some of the other powerful observability tools include Better Stack, New Relic, Sentry, Jaeger, AppDynamics, LogicMonitor, Honeycomb, and more. These tools help us understand the business better. Also, using the right tool can help us gain visibility, improve controllability, and valuable insight to ensure a smooth operation of the business.
Conclusion
On the whole, an observability strategy plays an important role in gaining insights into the state of your entire infrastructure, providing real-time insights to DevOps teams and software engineers. Furthermore, it enhances understanding of how the system interacts and performs with other components. With this comprehensive understanding, the teams can identify and address the issues before they become crucial.
Additionally, adopting observability as code can offer numerous benefits, including increased efficiency, automation and collaboration.
To sum up, observability stands as a key factor in enhancing security, reducing IT costs, improving performance and more.
Frequently Asked Questions
1. How is observability linked to the DevOps concept?
Observability and DevOps are interlinked concepts that help to attain the same goals. The main goal of observability is to ensure effective software deployment and support targets.
2. What are the key features of an observability tool?
User-friendly, real-time data, event handling capabilities, provides context and delivers business value.
3. How to implement observability?
Observability can be implemented by having proper tools and apps to gather suitable telemetry data. Observable systems can be made by building your tools, or by using open-source software. The implementation of observability typically involves four key components. Firstly, Instrumentation involves measuring instruments that collect telemetry information from the services, hosts, services and applications providing visibility across the entire infrastructure. Secondly, Data correlation entails preparing the collected telemetry data, and facilitating automated data curation. Thirdly, Incident response employs automated technologies planned to get data about outages to the right teams. Finally, AIOps employs machine learning modules to correlate, aggregate, and detect issues that impact the system.
4. How is observability related to cloud-native?
Due to the nature of the architecture, observability becomes particularly important. Since cloud native software uses microservices, the capacity to view interactions using observability data is crucial. This data can be used to trace overall resources and monitor those containers. Ultimately, the data ensures that the application is working properly and increases overall performance.
5. What are the best IT monitoring tools?
The best IT infrastructure monitoring tools are New Relic, Signoz, Middleware, Prometheus, Elastic Stack and many more.




